
Be honest, ever wanted to play “Steve Souders” for a day and pull some cool stats or trends about some web sites of your choice? Well, how about setting up your own HTTP Archive then?
Httparchive.org is an excellent tool to track, monitor and review how the web is built. You can dig into trends around page size, page load time, CDN usage, distribution of different mimetypes and many other stats.
You can download an HTTP Archive MySQL dump and the source code from the download page and play around yourself with the current data. For example, do what Stoyan Stevanov did by asking yourself some questions: “Hm, I wonder what are common mime types these days”. Once you’ve setup the database, you can easily query anything you want.
However, what I personally find the most intriguing and fun is applying all of this to sites of of your choice. Alright, let’s break this down: if you’re famous and your site is listed under the Top * Alexa sites, then you can use the official dump, if your target site is a wee bit less famous and not part of any of the crawled sites, you might want to start using your own database and local instance of HTTP Archive. That way, you can run this handy tool on any of the web sites you want to test.
Things to consider before you get started
You need MySQL, PHP and your own webserver running. If you choose to run your own private instance of WebPagetest, you won’t have to request an API key. I decided to ask Patrick Meenan (pmeenanATwebpagetestDOTorg) for an API key with limited query access. That’suffcient for me for now, if I ever wanted to use more WebPagetest runs per day, I’d probably want to setup a private instance of WebPagetest. I’ve done this before but my computer had to be replaced, and I haven’t had the time after to set this up again.
Sample setup
- Check out the latest source code
- Get the latest DB schema and some real data from here
- settings.inc: Setup your database info
- dbapi.inc: Setup of table names (you can leave this mostly as is)
bulktest: That’s the folder you really want to understand and work with when setting up your own little HTTP Archive baby.
- bulktest/README.txt: This file gives you a general intro on how to use the folder, I recommend to read this.
- bulktest/bootstrap.inc: In case you choose to us a private API key for WebPagetest, you will need to update this file with the provided key
To run a nice little batch, you want to execute the following scripts after each other via CLI (default setup for security reason)
- bulktest/batch_start.php: This script takes pre-defined list of URLs (importurls.php) that you can specify or change. By default it’s downloading the latest Alexa list (downloadAlexList()) and imports those into the urls table. I’ve changed this so it’s picking up my own csv file with the urls I want to crawl but you can also customize this the way you want it (default setup needs to run via CLI)
- bulktest/batch_process.php: Run this as often after each other until you get confirmation that your runs were successfully recorded (default setup needs to run via CLI)
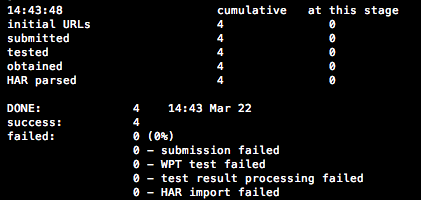 It always gives you a nice batch summary at the end so you know where you are at (see screenshot)
It always gives you a nice batch summary at the end so you know where you are at (see screenshot)
- bulktest/statscompute.php: This is needed for the rendering of the stats under your local URL, e.g. http://localhost/httparchive (default setup needs to run via CLI)
More detailed steps on how to install HTTP Archive can be found under the blog post Setting up HttpArchive private instance. As suggested by the README.txt file and this blog post, it’s probably useful if you setup cronjobs in your environment to automate the batch steps.
Front-end piece: Visualizing your trends and stats by filling the charts
Congrats! Assuming you’ve successfully setup your own HTTP Archive instance – wasn’t that fun and the bit of pain worthwhile? Now you can start viewing those charts and investigating trends and stats targeted to your defined URLs. The beautiful thing about having your own instance is that you can be your own master of data visualization: you can now create additional charts beside the ones that came out of the box provided by the default HTTP Archive setup.
And if you don’t like Google chart tools, you may even want to check out d3 or Highcharts to use instead.
From now on, the sky is the limit. Nobody can stop you now, my friend – you can even run some kick-ass raw database queries if you don’t really care much about the front-end visualization (I do ;))
Back-end piece: Querying the database directly
Sometimes, you want to get some questions answered without creating a pie or a chart. That’s when you can make use of the MySQL tables directly that have been setup for you (via schema sql file and filed by your batches).
Let’s run a simple query on the requests table.
For example, some of our sites use YUI, some use JQuery – but we would really like to avoid having pages serve both.
A simple sample query like the one below could help identify those sites:
select req_referer from requests where url like '%/i/l/yui%' or url like '%jquery-%.js' group by req_referer
Be prepared, some setup time is required
I’m not going to lie, it took me some after-work evenings, many debug statements via PHP to set everything up so I could run proper batch_start and a proper batch_process commands and fill in those pies and trends. Here are a few things to watch out for
- I hadn’t installed pcntl with my PHP version, so I needed to set this up first. You will need this to run batch_process.php. Installing pcntl for php on osx Lion blog post helped a lot – Thank you Jacob!
- You might have to adjust some of the tables values, I got lots of mysql insert/update errors regarding default values not set for certain fields
- After I received my API key, I still had to change the WebPageTest URL after Patrick pointed me to the correct URL (Thanks again). The $gWPTUrl variable was set to http://httparchive.webpagetest.org as default instead of http://webpagetest.org in settings.inc
- Some of the tables require you to have a temp/dev version of it as well, e.g. requests, urls, statsdev etc. Some of the scripts look for e.g. requestsdev. You might have to copy a few of the original tables during setup process. You can setup the naming convention in dbapi.inc
Next Steps
Where am I at? Well, I just finished a few successful batch_processes on a selected number of URLs. It’s fun to monitor trends based on the URLs I put in. I will be collecting more ideas and uses cases over the next few months, possibly also adding some more charts applicable to my needs.
If time permits, I hope to be sharing more of my customization and use cases of HTTP Archive at this year’s Velocity conference in San Jose. And if not there, I’ll try to update this blog post as best as possible. If you have any questions or suggestions, please leave a comment below.
I am always happy to receive feedback or happy help out with some roadblocks while setting this all up.
Thanks
to….
- sundergs for their helpful blog post Setting up HttpArchive private instance
- Stoyan’s post http://www.phpied.com/digging-into-the-http-archive/
- Patrick Meenan for providing me with a WebPagetest API key and helping sort out some API call issues I had
2 comments for “Setup your own HTTP Archive to track and query your site trends”