
The following post outlines the links, tools and articles I mentioned in my 3rd party footprint talk
Main Slides
Slides (Webdirections, Melbourne) and Slides (Velocity NYC 2014) and Web Rebels in Oslo
Shared Links and Articles
- Third-Party JavaScript (Ben Vinegar): http://thirdpartyjs.com/
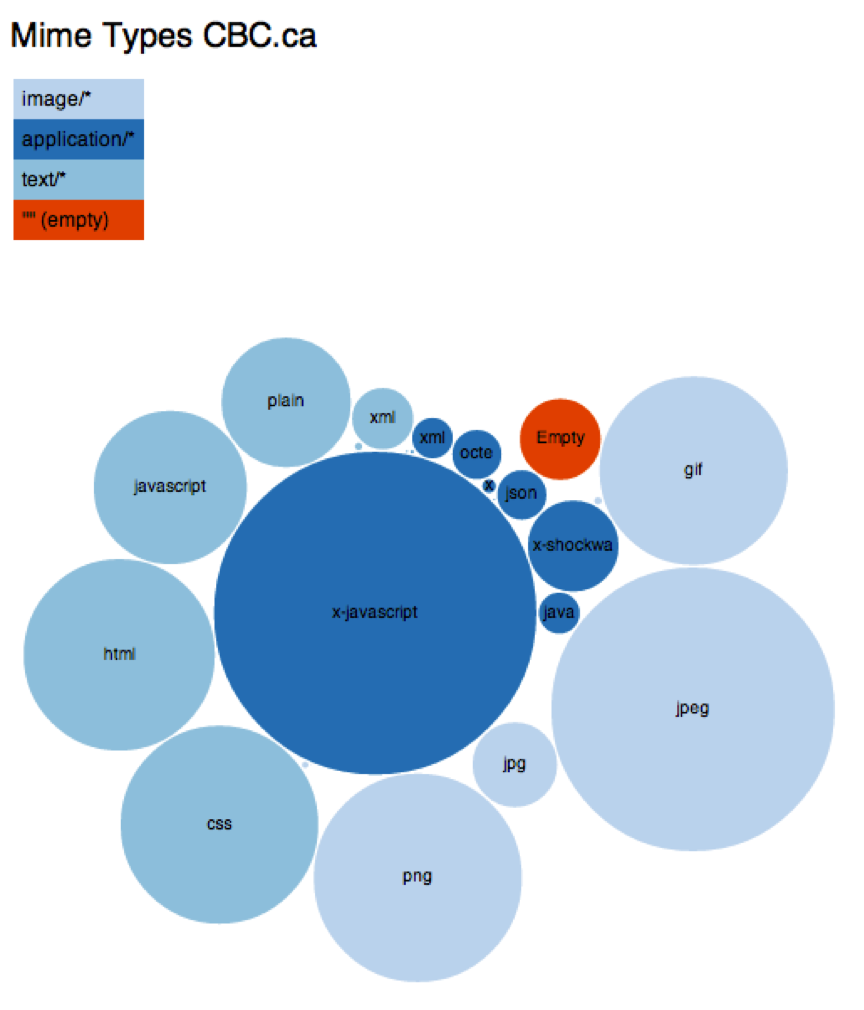
- HTTP Archive: httparchive.org
- Big queries: interesting stats: http://bigqueri.es/t/what-is-the-distribution-of-1st-party-vs-3rd-party-resources/100/4
- The impact of third party content on retail web performance: http://intechnica.co.uk/the-impact-of-third-party-content-on-retail-web-performance.aspx
- How we Make JavaScript Widgets Scream https://www.youtube.com/watch?v=4rlbTVkyJc4
- Nielsen and promotional space http://www.useit.com/alertbox/response-times.html
- Pat Meenan: Front-end SPOF: http://www.slideshare.net/patrickmeenan/frontend-spof and http://blog.patrickmeenan.com/2011/10/testing-for-frontend-spof.html
- Government UK, adding social buttons did not increase their traffic dramatically: https://insidegovuk.blog.gov.uk/2014/02/20/gov-uk-social-sharing-buttons-the-first-10-weeks/
- Steve Souders, Caching policies: http://www.stevesouders.com/blog/2012/03/22/cache-them-if-you-can/
- Steve Souders, Don’t doc write: http://www.stevesouders.com/blog/2012/04/10/dont-docwrite-scripts/
- Asynchronous List: https://developers.google.com/speed/docs/insights/UseAsync
- Dynamic script or async/defer: https://www.igvita.com/2014/05/20/script-injected-async-scripts-considered-harmful/
Tools and Tricks
- Ghostery plugin: https://www.ghostery.com/en/
- 3 D Tilt Firefox Plugin: https://addons.mozilla.org/en-US/firefox/addon/tilt/
- Philips’ script loader pattern: http://www.lognormal.com/blog/2012/12/12/the-script-loader-pattern/ or Method Queue Pattern: http://www.speedawarenessmonth.com/the-non-blocking-script-loader-pattern/
- Stoyan’s dynamic script tag: http://www.phpied.com/social-button-bffs/
- SPOF-O-Matic: https://chrome.google.com/webstore/detail/spof-o-matic/plikhggfbplemddobondkeogomgoodeg
- 3PO plugin: http://www.phpied.com/3po/
- Continuos integration: Ebay & SPOF: http://www.ebaytechblog.com/2013/01/22/early-detection-of-frontend-single-points-of-failure/#.UyTqyeddW_I
- Command Line Interface SPOF: https://github.com/lafikl/spof?utm_content=buffer3bda5&utm_source=buffer&utm_medium=twitter&utm_campaign=Buffer
- Heise’s 2-click button: http://www.heise.de/extras/socialshareprivacy/
- JSManners: https://github.com/triblondon/thirdpartysla
WebPagetest Results
- Herold Sun: www.webpagetest.org/result/140222_EA_J3R/
- Wired: www.webpagetest.org/domains.php?test=140222_NH_J10&run=1&cached=0
- TechCrunch: http://www.webpagetest.org/video/compare.php?tests=140323_P3_GRK,140323_37_GRM
- SPOF Wired: http://www.webpagetest.org/video/compare.php?tests=140224_7X_28Q,140224_4K_28R
- Alexa AUS 139: myshopping.au.com http://www.webpagetest.org/video/compare.php?tests=140317_NE_P%2C140317_ZN_Q&thumbSize=200&ival=5000&end=visual
- Home Depot: http://www.webpagetest.org/video/compare.php?tests=140317_KM_5D%2C140317_EB_5E&thumbSize=200&ival=5000&end=visual
- TechCrunch: http://www.webpagetest.org/video/compare.php?tests=140319_9B_EKD%2C140319_00_EKE&thumbSize=150&ival=5000&end=visual
- Walmart passes SPOF test: http://www.webpagetest.org/video/compare.php?tests=140319_0S_HN4,140319_GJ_HN5
- Weather Network: http://www.webpagetest.org/video/compare.php?tests=140321_4B_DJ2%2C140321_9H_DJ3&thumbSize=200&ival=5000&end=visual
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}